AI memory infrastructure your security team can sign off on.
When you're running AI agents for thousands of users across departments, memory infrastructure is also a risk surface. Hebbrix is built to shrink that surface, not expand it. Isolation, auditability, and lifecycle management are part of the core architecture, not bolted on.
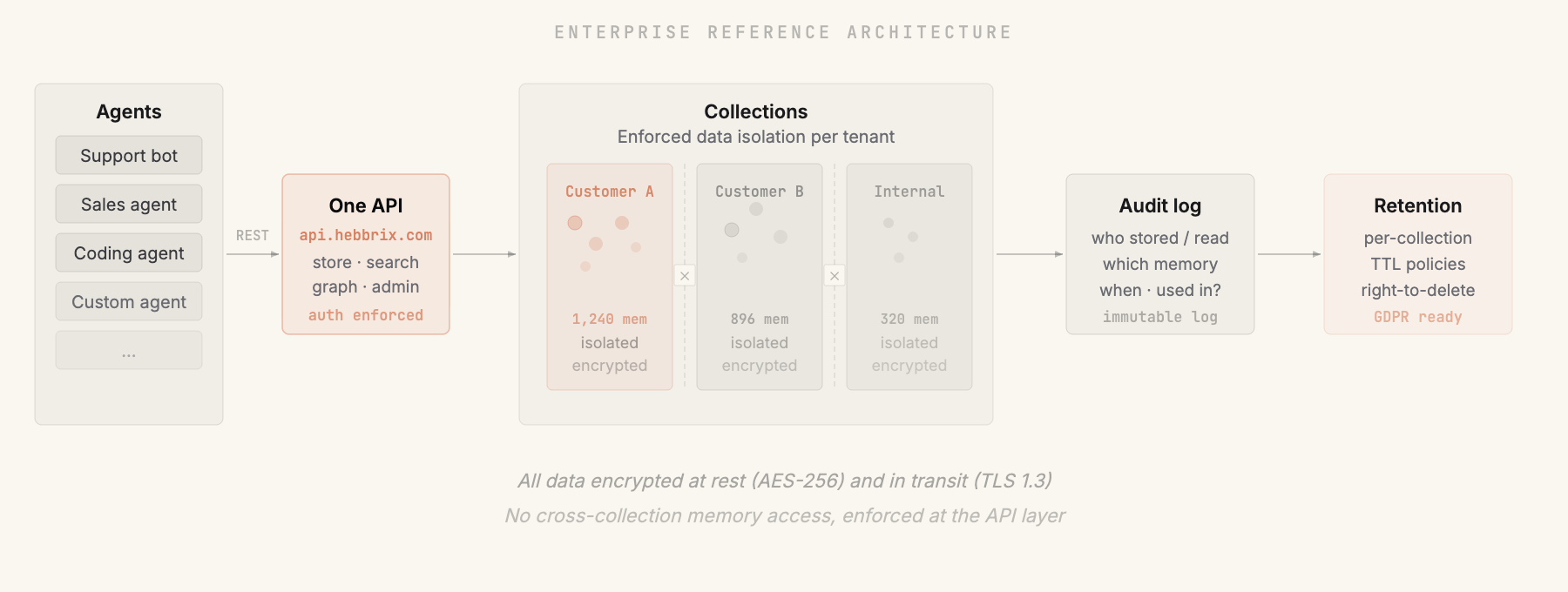
Every customer lives in their own memory space
Collections enforce hard boundaries. Customer A's memories can never appear in Customer B's context. That holds because of the architecture, not because of a configuration setting someone has to get right.
Building a POC is one thing. Production is another.
At enterprise scale, memory infrastructure has requirements that don't show up in a prototype.
Customer A's data can never appear in Customer B's context. Department boundaries must be enforced, not suggested. At scale, one context leak is a compliance incident.
You're not building for one user. You're building for thousands, each with their own memory space, permissions, and data lifecycle. That has to work natively, not through sharding logic you write and maintain yourself.
Sub-second retrieval with 100 memories is easy. Sub-second retrieval across millions of memories with thousands of concurrent users is an infrastructure challenge we've already solved.
Enterprise requirements are in the core architecture
Not bolted on. Not a checkbox on the pricing page. The architecture was designed with these requirements from the start.
Collections-based multi-tenancy
Every memory belongs to a collection. Collections enforce strict isolation. One API call creates an isolated memory space for any user, team, department, or customer. Serve 10,000 users from one instance without writing isolation logic yourself.
Full auditability
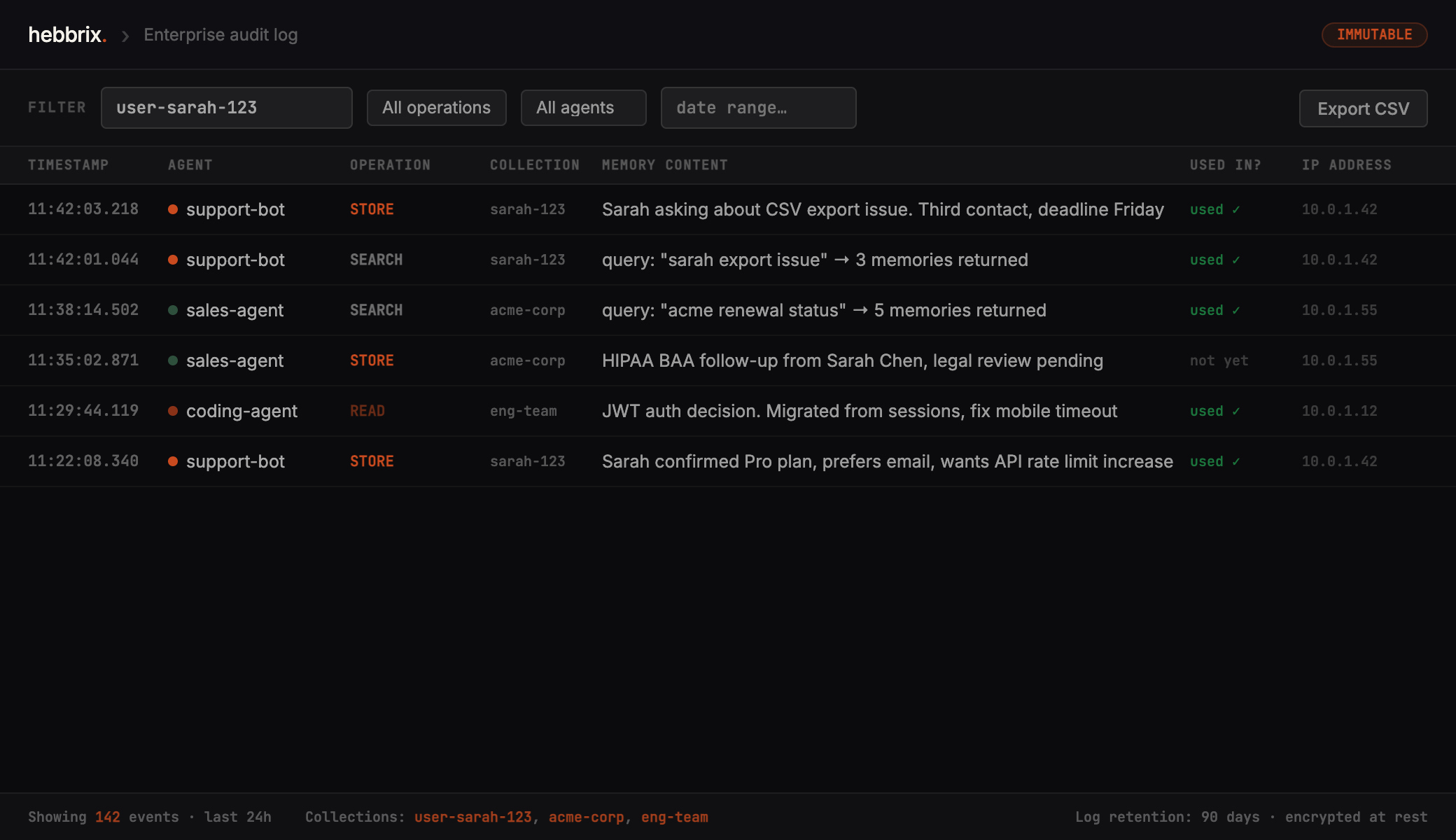
Every memory operation is logged. Know who stored what, when it was accessed, and how it was used in a response. When compliance asks "what data did this agent use?", you can answer it precisely instead of guessing.
Automatic data lifecycle
The Ebbinghaus forgetting curve is a retrieval feature, and it doubles as a compliance tool. Memories that aren't reinforced decay on their own. Pair that with explicit retention policies and you get data lifecycle management that matches how a real organization handles its records.
Memory-level access control
Flexible scoping lets you define read, write, and search permissions at the collection level. Build role-based access, department boundaries, or customer-specific memory spaces. The API enforces it. Your application doesn't have to.
What you need. What we provide.
Let's talk about your architecture
Start with the free tier to evaluate. When you're ready to scale, we'll help you design the right setup for your compliance requirements and team structure.