When agents work as a crew, memory should too.
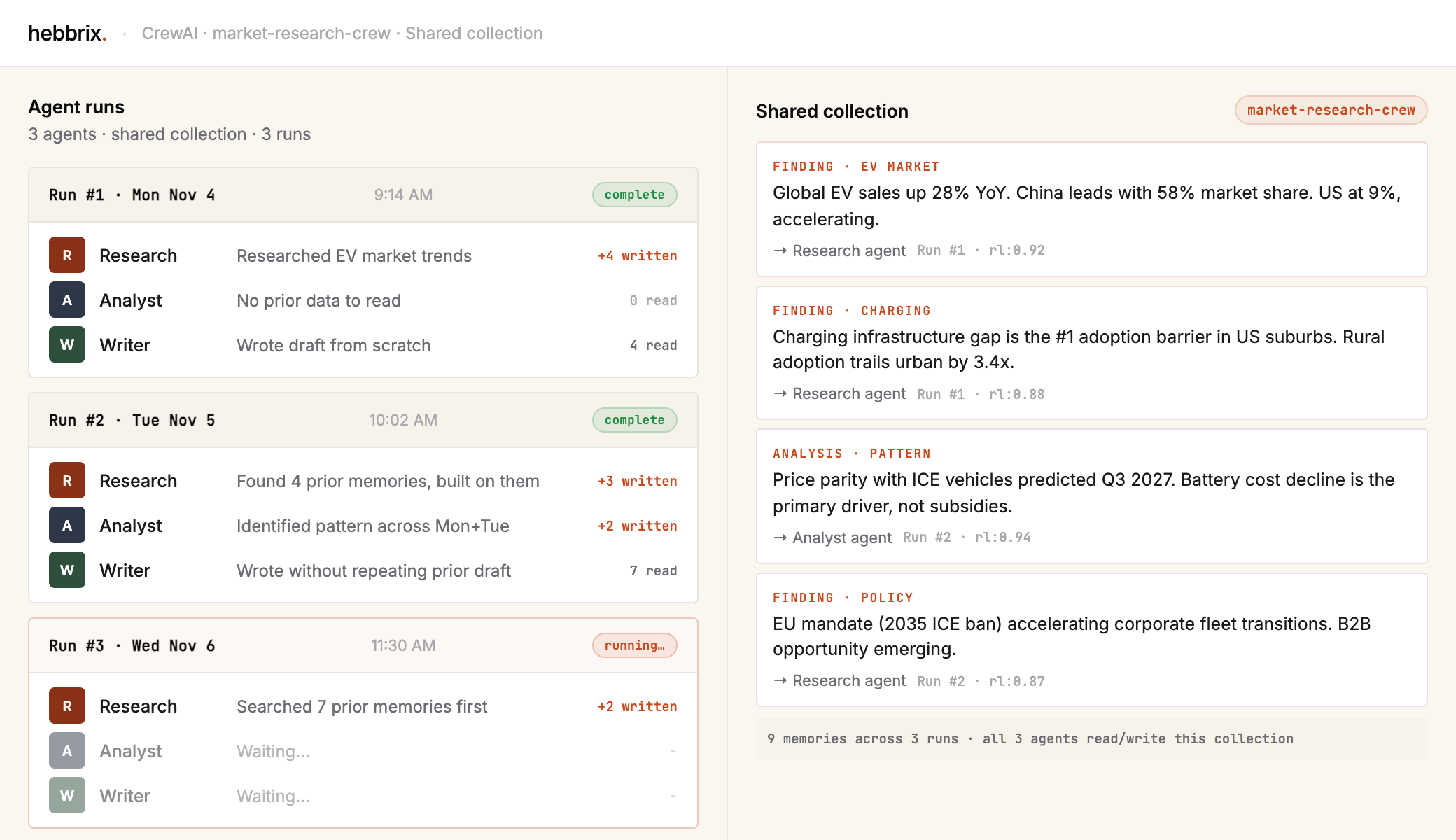
CrewAI coordinates agents well. But once the crew run ends, everything each agent learned disappears. Hebbrix gives every agent in your crew access to one shared, persistent memory, so the research agent's findings are available to the writing agent on this run and every run after.
Your crew's best work vanishes after every run
Each CrewAI run starts fresh. The research agent doesn't know what the analyst discovered last time. The writer doesn't know what the researcher found three runs ago. Every run is expensive; every lesson learned is thrown away.
With Hebbrix, each agent stores its findings in a shared collection. On the next run, or the next month, every agent can reach the full history of what the crew has learned.
from crewai import Agent, Task, Crew from hebbrix import MemoryClient API_KEY = "YOUR_API_KEY" COLLECTION = "market-research-crew" # MemoryClient is async-first async def research_task_fn(topic): async with MemoryClient(api_key=API_KEY) as mem: # Check what we already know past = await mem.search(topic, collection_id=COLLECTION) result = # ... do the research ... # Store for the crew await mem.add( content=result, collection_id=COLLECTION ) return result async def write_task_fn(topic): async with MemoryClient(api_key=API_KEY) as mem: # Writer reads what researcher stored research = await mem.search(topic, collection_id=COLLECTION) return write_with_context(research)
Memory that adds up run after run
Searches memory before it starts, so it doesn't repeat work. If a topic came up in a prior run, it builds on that instead of starting over, and cost per run drops as the memory fills out.
Sees the full history of what's been researched, so patterns and trends across runs become visible. One run's anomaly turns into the next run's confirmed finding.
Draws on everything the crew has ever found instead of repeating earlier outputs. It already knows the established positions, the open questions, and the prior conclusions.
Give your crew a shared brain
Every run makes the next one smarter. Free tier, no credit card required.