Vector search finds text. Graph RAG finds connections.
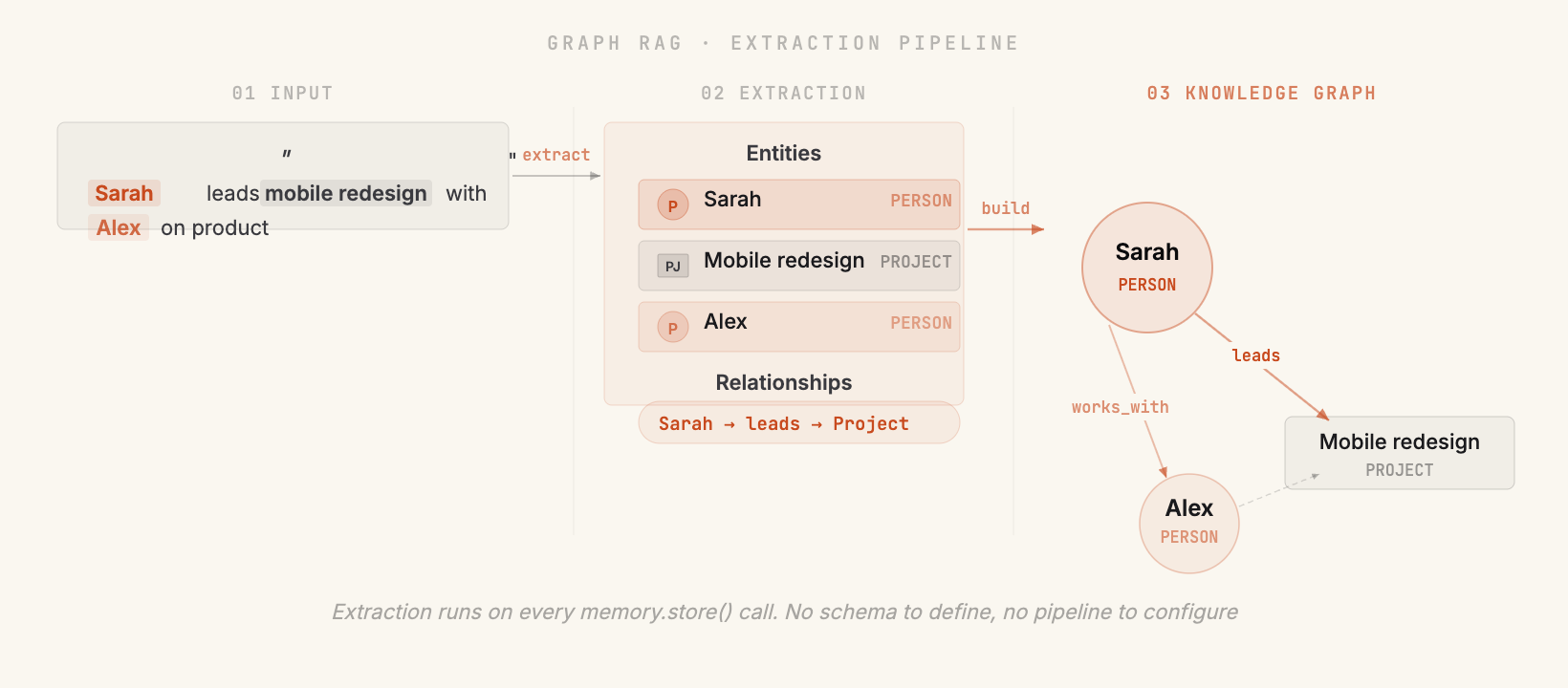
Hebbrix pulls the entities and relationships out of every memory you store. When your agent searches, it doesn't stop at matching embeddings. It walks the graph and finds answers that flat retrieval would miss entirely. You don't define a schema. You don't write extraction rules.
Same question. Completely different answer quality.
Vector similarity finds memories that sound like your query. Relationship traversal finds answers your query never explicitly asked for, because that knowledge lives in the structure, not the text.
Store text. Graph builds itself.
You don't define entity types, relationship schemas, or extraction pipelines. Store a memory in plain language and Hebbrix extracts the structure automatically. Every new memory enriches the graph without you touching anything.
No schema to define
Person, project, company, concept: Hebbrix recognizes them all on its own. You name the entities in plain English.
Graph grows with usage
Every memory adds nodes and edges. The more your agent learns, the richer the graph becomes.
Queryable directly
Use hebbrix.graph.search() for direct entity lookup, or let the hybrid search engine traverse it automatically.
from hebbrix import MemoryClient async with MemoryClient(api_key="YOUR_API_KEY") as mem: # Store plain text. No schema needed. await mem.memories.create( content="Sarah joined product team, reports to Jordan. " "She leads mobile redesign with Alex." ) # Hybrid search traverses the graph automatically results = await mem.search("Who is on Jordan's team?") # → Sarah (via reports_to relationship) # → Alex (via Sarah → works_with) # → Mobile redesign (via Sarah → leads) # Or query the graph directly entities = mem.graph.search("Jordan") # → Jordan → manages → Sarah # → Sarah → leads → Mobile redesign # → Sarah → works_with → Alex
Graph RAG that actually works in production
Graph traversal is one of five retrieval strategies running in parallel. You get the structured reasoning of graphs and the fuzzy matching of vectors at the same time, with no trade-off between them.
Graph traversal runs alongside vector search, not after it. The full 5-layer search, multi-hop graph hops included, finishes in under a second. It runs in production, not just in a research demo.
Relationships are timestamped. The graph knows when Sarah joined Jordan's team, and can answer "who was leading mobile redesign in October?" with historical accuracy.
RL quality checks run after every interaction. Graph edges that help produce accurate answers get reinforced. Stale or misleading relationships decay. The graph improves automatically.

Six domains where relationship reasoning changes everything
Map reporting structures, team membership, and authority chains from natural conversation. No org chart to maintain.
Link findings across papers, experiments, and datasets. Surface connections that span years of research.
Map stakeholders, influencers, and decision-makers across deal cycles. Know who to talk to without being told.
Connect symptoms, root causes, and fixes across tickets and postmortems. Find patterns invisible in flat text.
Map regulations to policies to implementations. Know what's covered, what's not, and why, with no manual tagging.
Connect features, dependencies, and feedback into a structured product knowledge base agents can reason about.
Add Graph RAG to your agent today
No schema definition. No extraction rules. Store memories in natural language and let the graph build itself. Free tier, no credit card.