Change one URL.
Your agent remembers everything.
Already calling the OpenAI API? Then you're about 30 seconds from giving your agent a memory. Hebbrix speaks the same format, so the SDK, the types, and the streaming all stay exactly where they are. Your agent just stops forgetting everything the second a session ends.
Two lines. That's it.
Hint: base_url and api_key. Everything else stays exactly the same.
Before
import openai client = openai.OpenAI() # No base_url → goes straight to OpenAI # Your agent has no memory of past sessions response = client.chat.completions.create( model="gpt-4", messages=[{"role": "user", "content": "What's my name?"}] ) # → "I don't have access to your name." # Every session starts from zero. Again.
After
import openai client = openai.OpenAI( base_url="https://api.hebbrix.com/v1", # ← add api_key="your_hebbrix_key" # ← add ) # That's the whole change. response = client.chat.completions.create( model="gpt-4", messages=[{"role": "user", "content": "What's my name?"}] ) # → "Your name is Alex. You told me # last Tuesday, discussing Acme Corp."
What happens between your message and GPT's response
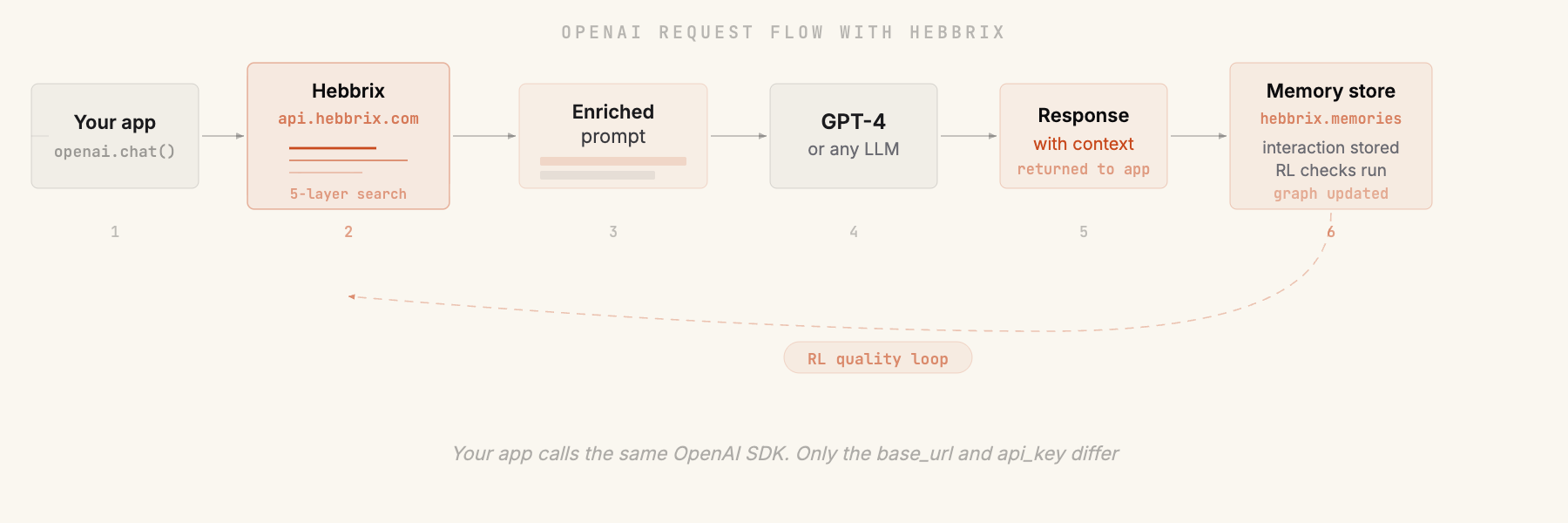
Your message arrives at Hebbrix
It comes in as the same JSON the OpenAI API already expects, with the same SDK methods and the same message shape. Your code has no idea anything changed, because on its side nothing did.
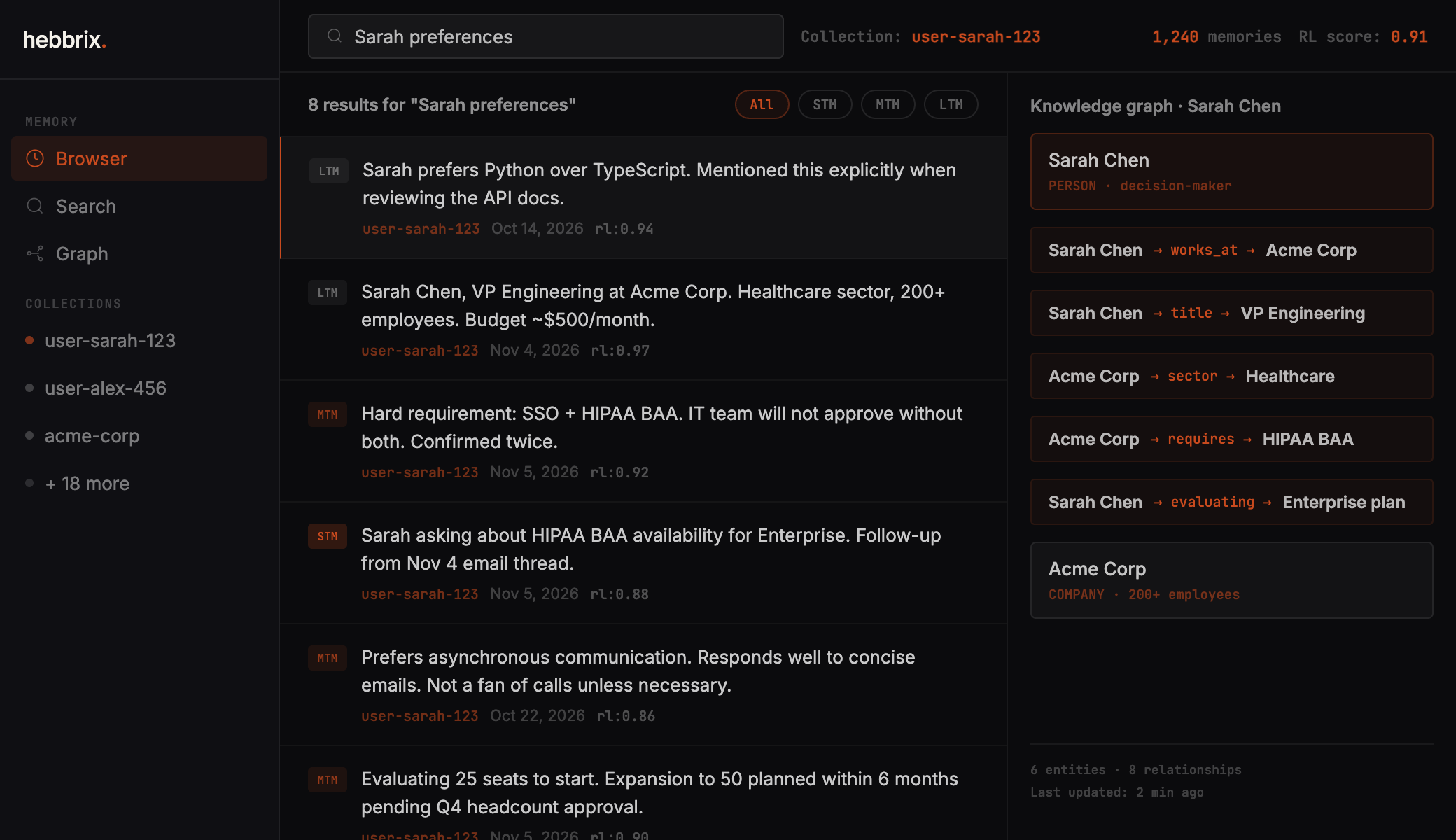
Five kinds of memory search run at once
Vector search, BM25 keyword matching, knowledge graph traversal, importance weighting, and recency all fire together and come back in well under a second. What you get is the context that actually matters for this specific question.
The relevant memory gets added to the request
Past preferences, earlier conversations, and related people or projects from the knowledge graph get folded into what the model sees. You never write the retrieval code yourself.
The fuller request goes to GPT-4
Hebbrix passes it along to the real model. Streaming, function calling, and JSON mode all behave exactly as they did before, and you get back a standard OpenAI response object.
The exchange becomes a memory
What you talked about gets stored, the important entities get pulled out, and the knowledge graph grows a little. Six quality checks run quietly in the background, so the next answer starts from a better place.
The whole memory stack, in one URL change
Three-tier memory
Short, medium, and long-term. Memories get promoted or fade on their own, the same way human recall follows the Ebbinghaus forgetting curve.
5-layer hybrid search
Vector, BM25, knowledge graph, importance, recency. Five signals, one sub-second query.
Automatic knowledge graph
Entity extraction and relationship mapping from every message. No schema to define, no pipeline to build.
Self-improving retrieval
6 RL quality checks after every interaction. Helpful memories are reinforced. Noise fades without you touching anything.
Natural memory decay
Old, irrelevant memories fade automatically. Context stays sharp even at production scale.
Zero migration
Same SDK, same types, same streaming. Change the URL and you're done. Ship memory this afternoon.
Try it in 30 seconds
If you have OpenAI code running right now, you can add memory before your coffee cools. Free tier, no credit card.