Your codebase has decisions. Your agent should know them.
Every commit message, PR description, and code comment holds a decision your team made. The Hebbrix GitHub connector reads your repository activity and turns it into searchable agent memory, so your coding agent knows why you use JWT, why you moved to TypeScript, and what the last outage taught you.
From commit history to agent knowledge
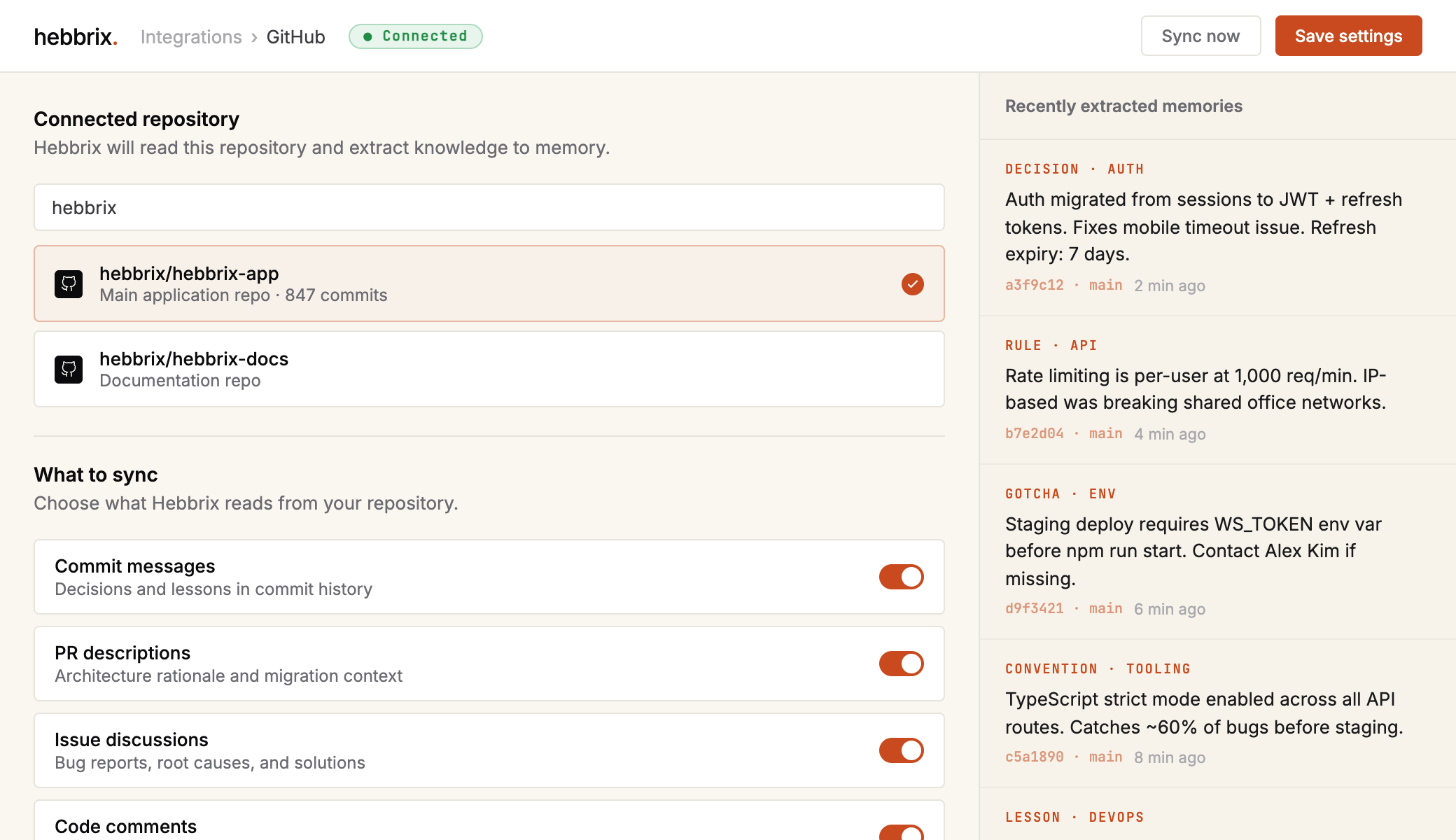
Hebbrix reads your repository and extracts the decisions, patterns, and lessons embedded in your commit history, PRs, and issues.
Your repository
Agent memory
Every piece of context your agent needs to understand your codebase
Decisions and lessons embedded in commit history. The why behind code changes.
Detailed context for architecture changes, migration rationale, and trade-offs.
Bug reports, reproduction steps, and solutions that took days to find.
Inline explanations of non-obvious patterns, temporary hacks with context, and TODOs with reasons.
Setup guides, architecture overviews, runbooks, and onboarding documentation.
What changed in each version, what was deprecated, what broke and what was fixed.
Let your agent know your codebase
Connect GitHub and give your coding agent the institutional knowledge it's been missing. Free tier, no credit card.