The answer is buried in Slack. Hebbrix pulls it out.
Your team's best knowledge lives in Slack threads: debugging sessions, architecture debates, customer insight, the quick fix that saved someone three hours. Agents can't search any of it, and it's buried under years of noise. The Hebbrix Slack connector pulls out the signal and turns it into persistent agent memory.
From Slack threads to organizational memory
Hebbrix watches the channels you pick and pulls the knowledge out of real conversations, including the context that makes that knowledge worth keeping.
Slack thread
Agent memory
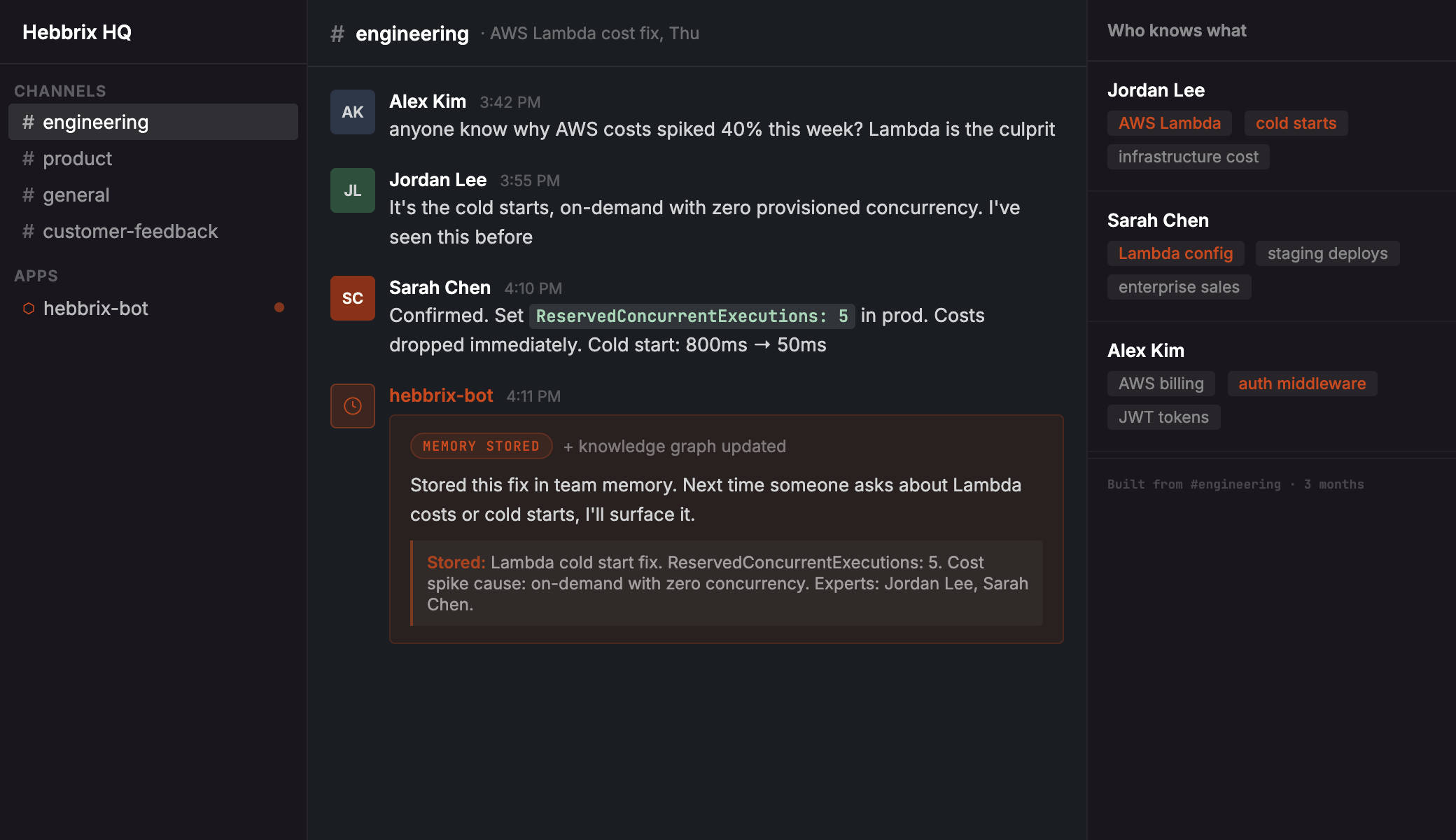
The organizational knowledge that usually gets lost
Bug fixes, architecture decisions, debugging sessions, deployment gotchas, AWS tips. The stuff that usually only lives in one person's head.
Support patterns, common objections, feature requests that keep coming up, workarounds your team has figured out.
Why you chose one vendor over another, why you delayed a feature, what the leadership debate was about. Context that never makes it into Confluence.
The knowledge graph automatically maps who on your team is the expert on what. Your agent knows to say "ask Jordan about Lambda" not just "Lambda is complex."
Hebbrix only reads channels you explicitly connect. Messages are processed to extract knowledge, and raw message content is never stored. DMs are never accessible.
Your team's knowledge deserves a better home
Connect Slack and let every agent on your team benefit from everything every other agent has learned. Free tier, no credit card.