Stateful graphs. Stateful memory.
LangGraph gives you precise control over agent state as it flows through graph nodes. Hebbrix makes that state persistent, so it survives restarts, sessions, and the jump from one user to the next. You define the graph state. We run the memory underneath it.
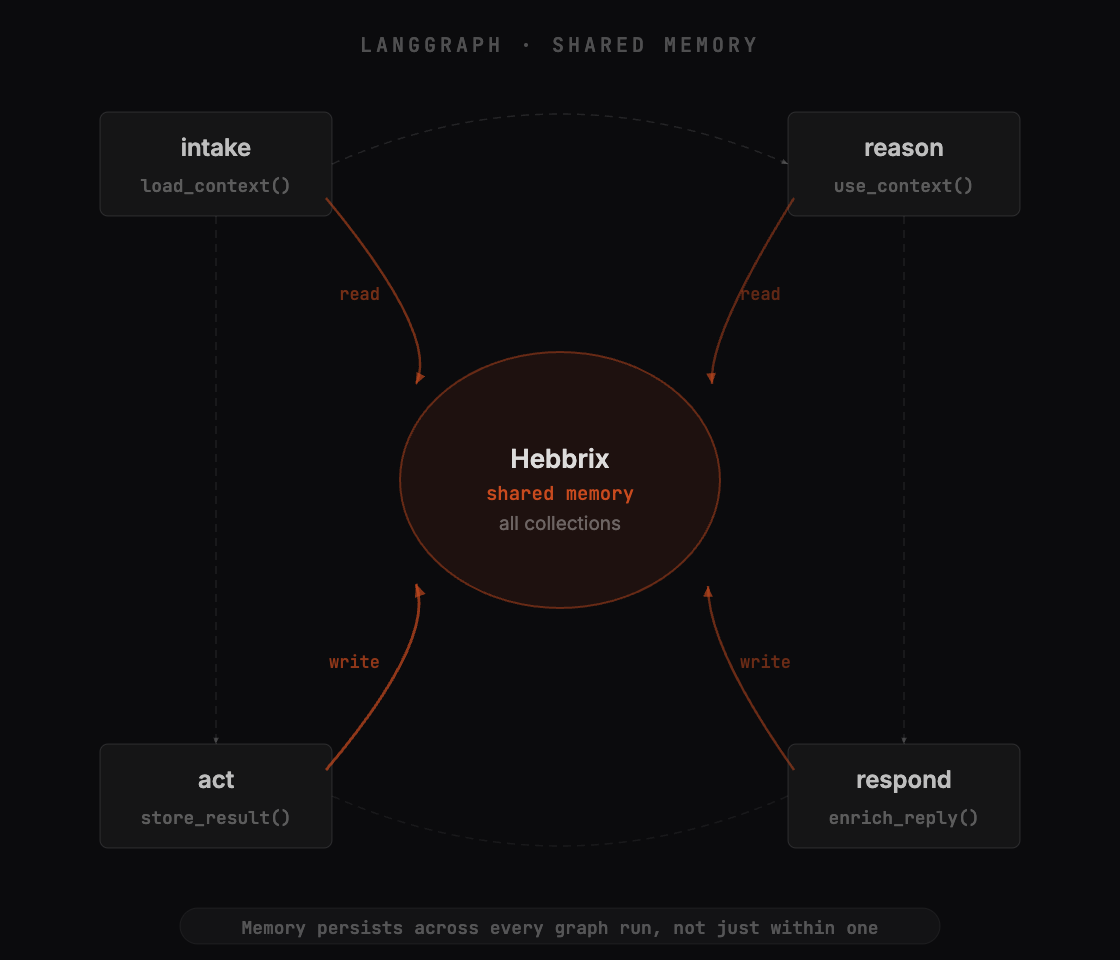
Every graph node reads and writes shared memory
Pass the Hebbrix client in your graph state. Any node can search memory before acting and store what it learned after. The memory isn't scoped to a single node. It's shared across the whole graph and every future run.
from langgraph.graph import StateGraph from hebbrix import MemoryClient API_KEY = "YOUR_API_KEY" # MemoryClient is async-first — nodes are async async def intake_node(state): # Load context before reasoning async with MemoryClient(api_key=API_KEY) as mem: ctx = await mem.search(state["input"]) return {"context": ctx} async def respond_node(state): response = await llm.ainvoke( state["input"], context=state["context"] ) # Store what this interaction taught us async with MemoryClient(api_key=API_KEY) as mem: await mem.add( content=state["input"] + " → " + response ) return {"output": response} graph = StateGraph(AgentState) graph.add_node("intake", intake_node) graph.add_node("respond", respond_node)
Cross-run persistence
Every time your graph runs, it can reach every memory stored in every prior run. User preferences, past decisions, and earlier context are all available to every node.
Shared state across nodes
In-graph state is temporary. It lives for one run. Hebbrix memory sticks around, so a fact learned in the intake node is still available to the respond node three runs later.
Knowledge graph across graph runs
Each stored memory is analyzed for entities and relationships. Your graph can query "what's the relationship between X and Y?" even if they were mentioned in different runs months apart.
Three things LangGraph agents can't do without persistent memory
Learn from prior runs
An agent that ran last Tuesday remembers what happened. Next Tuesday's run picks up from there instead of from zero.
Reason about relationships
The knowledge graph connects entities across all runs. "Who authorized the decision?" is answerable even if the answer came from three separate graph executions.
Personalize across users
Collections let you scope memory per user, per team, or per project. The graph can serve 100K users and give each one their own context, with no code changes.
Your graph deserves memory that persists
Free tier. No credit card. Add persistent memory to your LangGraph agents today.